Abstract
We present Splat-MOVER, a modular robotics stack for open-vocabulary robotic manipulation, which leverages the editability of Gaussian Splatting (GSplat) scene representations to enable multi-stage manipulation tasks.
Splat-MOVER consists of:
- ASK-Splat, a GSplat representation that distills latent codes for language semantics and grasp affordance into the 3D scene. ASK-Splat enables geometric, semantic, and affordance understanding of 3D scenes, which is critical for many robotics tasks;
- SEE-Splat, a real-time scene-editing module using 3D semantic masking and infilling to visualize the motions of objects that result from robot interactions in the real-world. SEE-Splat creates a "digital twin" of the evolving environment throughout the manipulation task;
- Grasp-Splat, a grasp generation module that uses ASK-Splat and SEE-Splat to propose candidate grasps for open-world objects. ASK-Splat is trained in real-time from RGB images in a brief scanning phase prior to operation, while SEE-Splat and Grasp-Splat run in real-time during operation.
We demonstrate the superior performance of Splat-MOVER in hardware experiments on a Kinova robot compared to two recent baselines in four single-stage, open-vocabulary manipulation tasks, as well as in four multi-stage manipulation tasks using the edited scene to reflect scene changes due to prior manipulation stages, which is not possible with the existing baselines.
Splat-MOVER
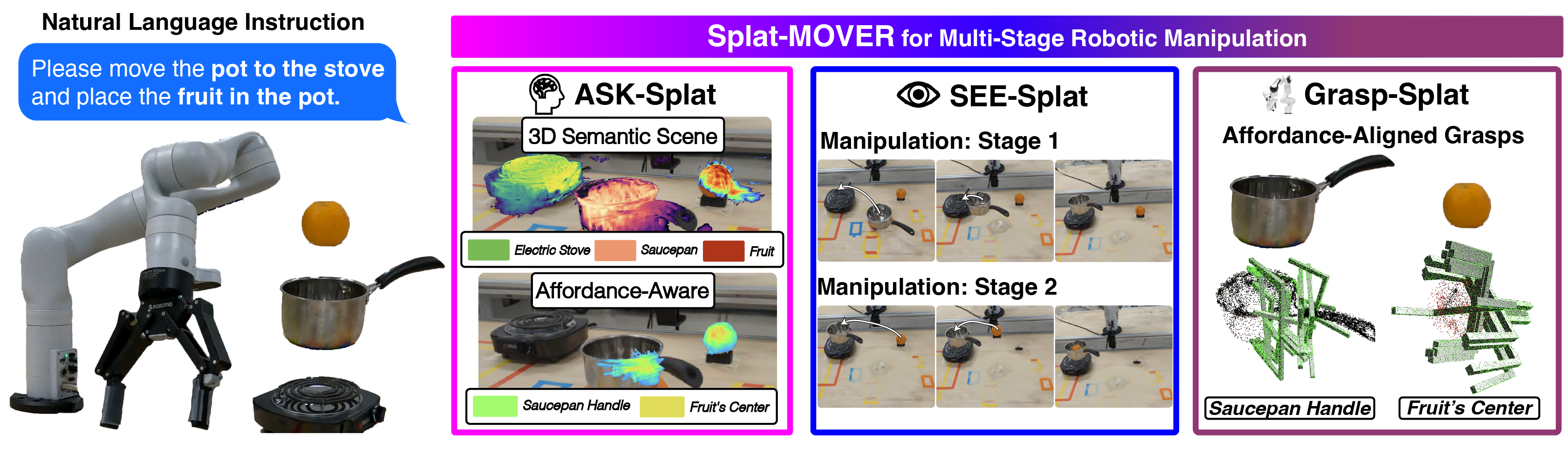
Splat-MOVER enables language-guided, multi-stage robotic manipulation, through an affordance-and-semantic-aware scene representation ASK-Splat, a real-time scene-editing module SEE-Splat, and a grasp-generation module Grasp-Splat.
Given a natural language description of a multi-stage manipulation task, Splat-MOVER utilizes the affordance-and-semantic-aware ASK-Splat scene representation to localize and mask the objects specified by the natural language prompt in the 3D scene, providing specific initial and target configurations for the robotic manipulator at each stage of the manipulation task. Subsequently, SEE-Splat edits the ASK-Splat scene in real-time, reflecting the current state of the real-world scene, thereby enabling its use in multi-stage manipulation task. Leveraging object-specific grasp affordance codes from ASK-Splat, Grasp-Splat generates candidate grasp configurations for each object, at each stage of the manipulation task.
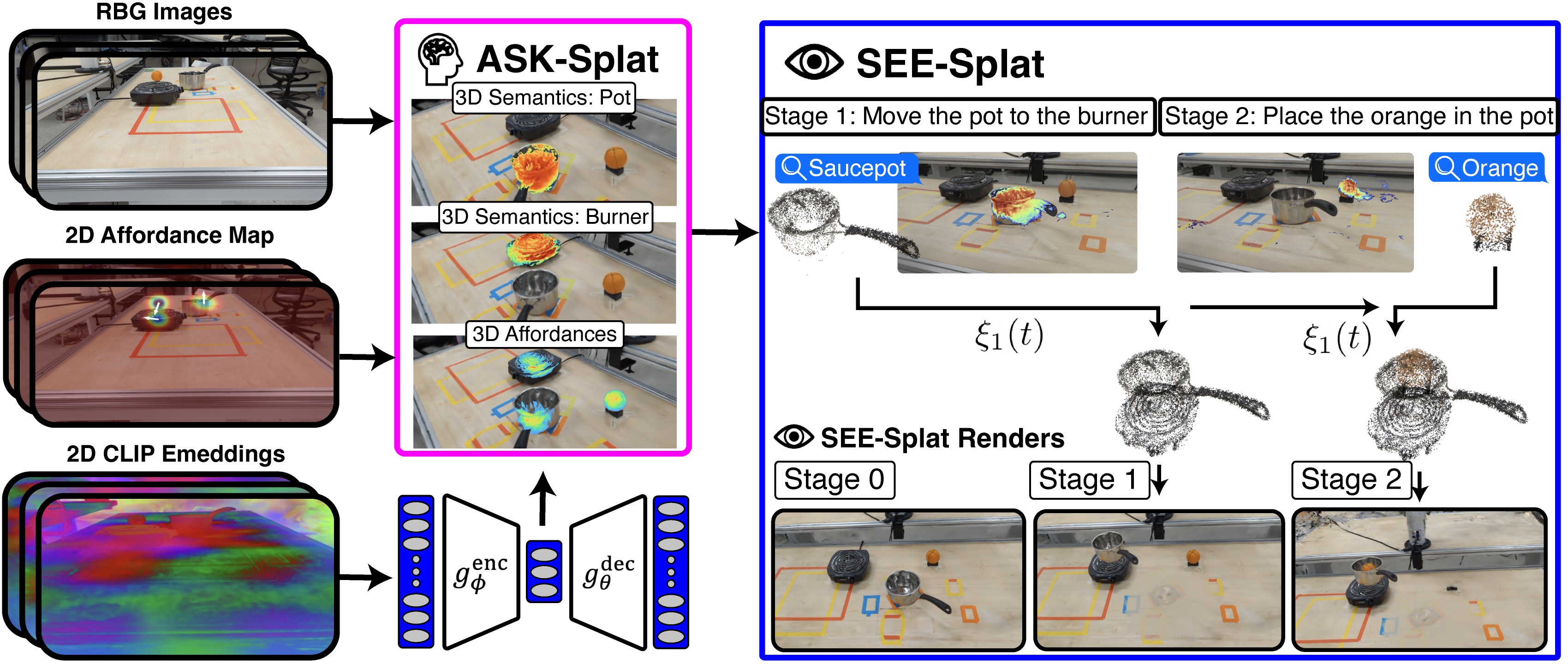
ASK-Splat grounds 2D visual attributes (e.g, color and lighting effects), grasp affordance, and semantic embeddings within a $3$D GSplat representation and is trained entirely from RGB images. Leveraging 3D ASK-Splat, SEE-Splat enables open-vocabulary scene-editing via semantic localization of relevant Gaussian primitives in the scene, followed by 3D masking and transformation ξ of these Gaussians.
ASK-Splat
ASK-Splat encodes semantic and affordance knowledge distilled from 2D foundation models in the 3D GSplat scene representation. For semantic knowledge, we distill vision-language features from CLIP a 2D foundation model for predicting image-text similarity. We leverage the MASKCLIP feature distillation method to extract pixel-wise image features from CLIP and embed them as attributes of the Gaussians during training of the GSplat representation. Further, we distill grasp affordances from a pre-trained 2D vision-based affordance model, Vision-Robotics Bridge (VRB) which predicts a set of contact points given an image. VRB is trained from videos of humans conducting manipulation tasks. We post-process the resulting output of VRB to obtain dense pixel-wise grasp affordance codes, which are embedded as attributes in the ASK-Splat Gaussians during training. ASK-Splat adapts the concepts of a distilled feature field (DFF) from the NeRF literature to the Gaussian Splatting (GSplat) model representation. ASK-Splat trains online from RGB images collected in a brief training phase prior to robot operation.
SEE-Splat
Leveraging ASK-Splat, SEE-Splat enables real-time scene-editing by extracting relevant objects from the ASK-Splat scene through a semantic 3D masking process, and subsequently moving these objects in 3D, by applying a transformation specified by a function describing the desired motion. We use SEE-Splat to reflect the movements of objects made by a robot as it carries out multi-stage manipulation tasks, so that later stages of the task can build upon the results of earlier stages (e.g., moving a saucepan to the stove, then putting a fruit in the saucepan). Moreover, SEE-Splat enables visualization of the evolution of the scene prior to the execution of the robot's plans.
Grasp-Splat
Grasp-Splat leverages the affordance and semantic codes embedded in the ASK-Splat scene to propose candidate grasp poses that are more likely to succeed. Grasp-Splat takes an open-vocabulary task command and produces 3D segmentation masks for the relevant objects using ASK-Splat's embedded semantic codes. It then queries the pre-trained grasp proposal model GraspNet to produce a set of grasp candidates for the objects, and re-ranks these candidates based on alignment with the grasp affordance codes embedded in the ASK-Splat scene. Following the grasp generation, Grasp-Splat selects and executes the best grasp to accomplish the sub-task.
Hardware Experiments
We showcase Splat-MOVER's effectiveness through hardware experiments on a Kinova robot, where Splat-MOVER achieves significantly improved success rates across four single-stage, open-vocabulary manipulation tasks compared to two recent baseline methods: LERF-TOGO (using the publicly-available code implementation) and F3RM* (implemented by the authors of this work). In three single-stage manipulation tasks, Splat-MOVER improves the success rate of LERF-TOGO by a factor of at least 2.4, while achieving almost the same success rate in the last task (95% compared to LERF-TOGO's 100%). Likewise, Splat-MOVER improves the success rates of F3RM* by a factor ranging from about 1.2 to 3.3, across the four single-stage manipulation tasks. We provide a brief summary of the performance of each algorithm in the hardware experiments in the table at the end of this subsection.
| Methods | Saucepan | Knife | Cleaning Spray | Power Drill | ||||
|---|---|---|---|---|---|---|---|---|
| Grasping Success (%) | AGSR (%) | Grasping Success (%) | AGSR (%) | Grasping Success (%) | AGSR (%) | Grasping Success (%) | AGSR (%) | |
| LERF-TOGO | 40 | 5 | 35 | 35 | 25 | 15 | 100 | 0 |
| F3RM* | 30 | 30 | 60 | 60 | 75 | 40 | 70 | 70 |
| Splat-MOVER | 100 | 60 | 85 | 85 | 90 | 90 | 95 | 95 |
In addition, we demonstrate the superior performance of Splat-MOVER in four multi-stage manipulation tasks, where we leverage SEE-Splat to reflect the updates in the scene resulting from prior manipulation stages, a capability absent in existing baseline approaches. We provide detailed results in our paper.
Candidate grasps for a saucepan, knife in a guard, cleaning spray, and power drill (from top-to-bottom), generated by GraspNet, LERF-TOGO, F3RM*, and Grasp-Splat (from left-to-right). GraspNet does not consider the semantic features of the object in generating candidate grasps; as a result, the proposed grasps are not localized in regions where a human might grasp the object, unlike the candidate grasps proposed by F3RM*, LERF-TOGO, and Grasp-Splat. Although LERF-TOGO and F3RM* require the specification of a grasp location from an operator, an LLM, or via human demonstrations to generate more-promising candidate grasps, Grasp-Splat generates candidate grasps of similar or better quality without requiring external guidance.
Video
BibTeX
@article{shorinwa2024splat,
title={Splat-MOVER: Multi-Stage, Open-Vocabulary Robotic Manipulation via Editable Gaussian Splatting},
author={Shorinwa, Ola and Tucker, Johnathan and Smith, Aliyah and Swann, Aiden and Chen, Timothy and Firoozi, Roya and Kennedy, Monroe David and Schwager, Mac},
booktitle={8th Annual Conference on Robot Learning},
year={2024}
}